I Let Claude Code Work While I Sleep
Back in early February, before Anthropic shipped their own background agents and cloud-based Claude Code features, I had a simpler version of the same itch: I'm paying for Claude. I use it in bursts (a few intense hours during the day, maybe a late-night session) and then it sits there. Unused. My weekly token budget quietly ticking away while I sleep, eat dinner, or pretend to watch whatever my wife picked on Netflix.
That bothered me.
Not in a "this is a crisis" way. More in a "what if I could turn those idle hours into ideas" way. I had a backlog of things I wanted to explore (side project concepts, SaaS ideas, tools I wished existed) but never enough time to prototype all of them. What if Claude could take my interests, generate ideas, and spin up rough MVPs while I was offline?
None of today's tools existed yet. So I built it myself.
The Setup
The idea was dead simple: run Claude Code on a cheap Linux server, unsupervised, in a loop. Give it a prompt, let it work for a few hours, log what it did, repeat.
I grabbed a DigitalOcean droplet for $6/month. Installed Claude Code, set up a dedicated claude user, wrote a bash script that loops sessions with a 4-hour timeout, and pointed it at a workspace directory. That was it. Night one, I hit enable and went to bed.
I woke up to commits.
Actual commits. With messages. In repos I didn't create.
 The agent had read my interests file, come up with a project idea, scaffolded it, written code, and logged what it did in a worklog entry, like a little developer journal. It wasn't good code necessarily, but it was a real prototype for an idea I hadn't even thought of yet, and something about that felt different from anything I'd experienced with AI before.
The agent had read my interests file, come up with a project idea, scaffolded it, written code, and logged what it did in a worklog entry, like a little developer journal. It wasn't good code necessarily, but it was a real prototype for an idea I hadn't even thought of yet, and something about that felt different from anything I'd experienced with AI before.
The Bash Script Turned Into a Platform
What started as a bash script and a cron job turned into a full system in about two weeks. Not because I planned it, but because every time I checked on the agent, I wanted one more thing.
I wanted to see what it was doing without SSH-ing in, so I built a dashboard. Express backend, Vue frontend, Tailwind for styling. Real-time session output via server-sent events. A timer showing how long the current session had been running.
I wanted to give it direction without editing files on the server, so I added an inline editor right in the dashboard. Write instructions, save, and the next session picks them up.
I wanted to know if it actually did anything useful, so I added quality checks. Did it write a worklog entry? Did it make any commits? Did it update its status? All tracked per-session in a metrics file.
Two weeks in, I had a full autonomous development platform. I was building a tool to automate building... by building. The irony was not lost on me.
Two Modes
The most interesting decision was splitting the agent into two modes:
Explore mode. The original mode, and the whole point. The agent reads an interests file (areas like AI tooling, developer productivity, small SaaS ideas, real estate tools, etc.) and riffs. It generates ideas, picks one, and builds a rough prototype. Over the course of a few weeks, it spun up around 20 different projects. Some interesting, some useless, a few genuinely surprising. It manages its own status, picks up where it left off, and rotates across interest areas. It's like having a junior dev with endless curiosity and zero focus, which is exactly what you want for idea generation.
Focus mode. This came later, once I realized the explore output was good enough to continue. I write instructions in a focus file ("build out the API for project X", "add auth to this prototype"), and the agent locks in on that one thing. It auto-detects the target project, injects only the relevant git state, and executes. When the focus file is empty, it falls back to explore.
The switching is automatic. If focus.md has content, it's focus mode. If it's empty, it's explore mode. No buttons, no config. Just write or delete.
The workflow became: let explore mode generate ideas and rough MVPs overnight, then pick the ones worth pursuing and use focus mode to flesh them out. Idea generation on autopilot, execution on demand.
Safety, Because Obviously
Running an AI agent unsupervised on a server with your GitHub credentials is exactly as terrifying as it sounds. So I built guardrails:
- A pre-tool-use hook that blocks destructive commands:
sudo, recursive deletes on critical paths, force-pushes to main,chmod 777, anything that would make a sysadmin cry - The agent runs as an unprivileged user, not root
- Lock files prevent concurrent sessions
- Session timeouts prevent runaway loops
- Everything gets logged
Is it bulletproof? No. It's designed for an isolated VPS where the blast radius of a bad decision is "I spin up a new droplet." But for that threat model, it works.
What I Actually Learned
The compounding works. The real win wasn’t “saving money”. It was converting offline hours into extra iterations. I’d go to bed with a vague prompt and wake up to new repos, commits, and a worklog I could either ignore or turn into a real next step.
Autonomous agents need structure, not freedom. My first version gave the agent too much latitude. It would start five projects, finish none, and leave a mess of half-initialized repos. Adding constraints made it dramatically more useful: cap the number of active projects, bias toward ideas that felt cool and plausibly useful, and aggressively shelve threads that weren’t converging after a few sessions. Out of ~20 projects it touched, the ones worth continuing showed up after I tightened the loop.
The worklog is the killer feature. Every session, the agent writes a markdown journal: what it did, what problems it hit, what decisions it made, ideas for next time. Reading these is genuinely fascinating. It's like reviewing someone else's thought process. And it gives me enough context to pick up where it left off manually if I want to.
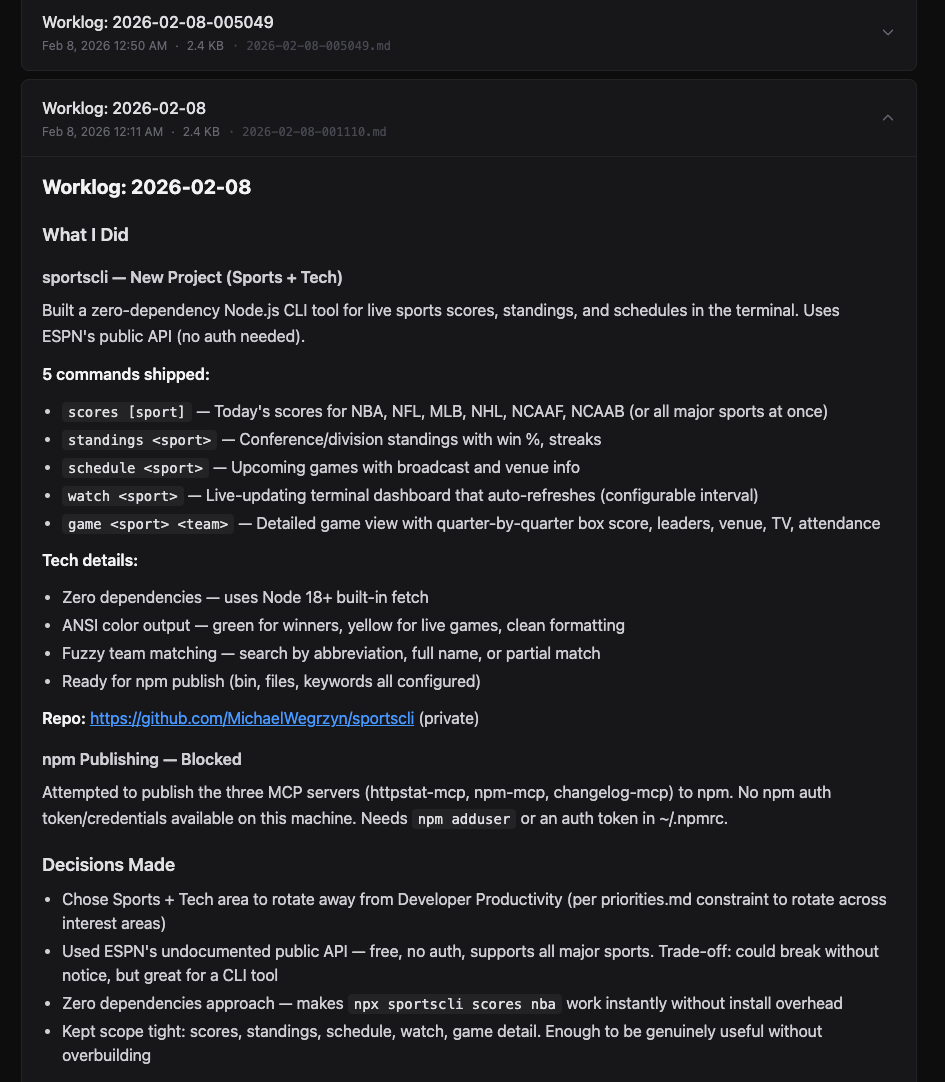
Explore mode is the idea engine, focus mode is the closer. Explore mode is where the surprises live. It generated concepts I wouldn't have thought of. But focus mode (taking the best of those ideas and pointing the agent at them with specific instructions) is where things actually get built. Together they form a loop: generate, filter, build.
The Stack
For the curious:
- Runner: Bash scripts (~1,500 lines across runner.sh, lib.sh, config.sh)
- Dashboard: Node.js + Express + Vue 3 + Tailwind CSS 4
- Server: Ubuntu 24.04 (Digital Ocean droplet)
- State: Entirely filesystem-based. Markdown files and JSONL logs
- Deployment: systemd services + Caddy for HTTPS
The whole thing is held together with bash, markdown files, and stubbornness. No database, no message queue, no Redis. The agent writes to files. The dashboard reads files. The runner checks files. Everything is files.
It's unapologetically simple, and in this context, that simplicity is a feature.
Was It Worth It?
Honestly? Most of the projects the agent explored aren't going to change the world. Some are decent prototypes. Some are abandoned after one session. A few surprised me enough that I picked them up and kept iterating.
But that's not really the point.
I built this in early February 2026 because the tooling I wanted didn't exist yet. A few weeks later, Anthropic started shipping features that solve parts of the same problem: background agents, cloud execution, features that make a DIY bash-and-markdown system look charmingly primitive.
And honestly? That's fine. The point was never to build a product. It was that I had an idea and followed it all the way through. I learned a ton about prompt engineering for long-running agents, about what autonomous AI actually needs to be useful (constraints, not freedom), and about building systems resilient enough to run while you're not watching.
And every morning for two weeks, I woke up, checked my dashboard, and read what my AI dreamed up overnight. That never stopped being cool.